Debugger jest nieocenioną pomocą przy takich programach jak emulator, ponieważ zachodzi potrzeba analizy działania zarówno naszej aplikacji jak i programu będącego uruchomionego w wirtualnym środowisku. W tym poście poruszę jedynie drugi przypadek.
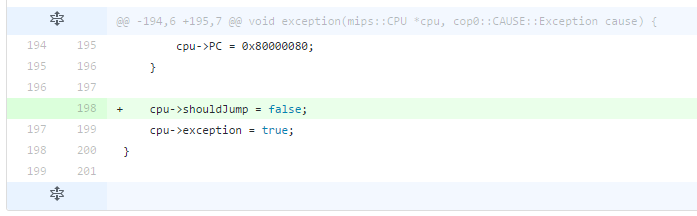
Gdy zaczynałem implementować procesor jedyną opcją było logowanie każdej wykonywanej instrukcji na standardowe wyjście:
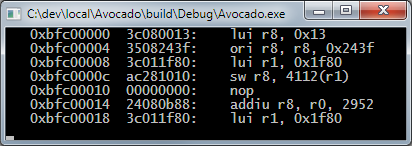
Trace
Takie rozwiązanie umożliwiało szybkie sprawdzenie czy instrukcje są poprawnie wykonywane i jak wygląda ścieżka wykonywania programu (porównując ją z wersją rozkompilowaną). Implementacja jest bardzo prosta - do każdej instrukcji jest doklejone makro, które używając sprintf-a formatuje daną instrukcję, a przy jej wykonaniu jest ona wyświetlana.
Rozwiązanie niestety nie sprawdza się gdy zachodzi potrzeba zatrzymania programu w danym miejscu. Można to rozwiązać wstawiając breakpoint z odpowiednim warunkiem w kodzie emulatora przed wykonaniem instrukcji, ale to spowalnia wykonywanie. Inny problem występuje gdy wykonywana jest pętla. Do terminala wyrzucane są tysiące powtarzających się instrukcji, które niewiele mówią o przebiegu i stanie programu.
Sensowną alternatywą wydaje się napisanie dekompilatora z możliwością debugowania. Ta funkcjonalność na pewno będzie zaimplementowana prędzej czy później, ale póki co wolę wybrać gotowe rozwiązanie.
GDB
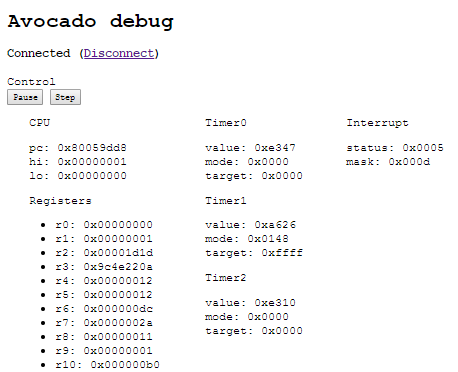
GDB w pełnej okazałości
GDB to debugger dostępny razem z pakietem GCC. Oznacza to że jest on dostępny na większość systemów operacyjnych i obsługuje wiele architektur (w tym MIPS). Jedną z interesujących opcji GDB jest działanie w trybie remote. Pozwala on na debugowanie programu w sytuacji, gdzie urządzenie nie jest w stanie zapewnić środowiska do działania GDB - przykłady to debugowanie jądra systemu (kgdb), debugowanie kodu na platformach embedded czy innych gdzie nie ma systemu operacyjnego. Zasadza działania tego trybu jest prosta - komputer łączymy z urządzeniem docelowym z użyciem portu szeregowego, a do wykonywanego programu dopisujemy funkcję obsługującą komunikację tzw. gdb stub.
Stub reaguje na kilka podstawowych komend - zrzuć i zapisz wartości rejestrów, odczytaj lub zapisz pamięć, kontynuuj wykonywanie. Komend są dziesiątki, ale wystarczy implementacja tylko 6 podstawowych, aby gdb zaczęło współpracować. Dzięki temu rozwiązaniu cała praca związana z dekompilacją kodu, podglądem pamięci i sterowania kodem wykonywana jest na komputerze.
Takie rozwiązanie implementują inne emulatory - QEMU umożliwia podpięcie do gdb i debugowanie programu działającego w maszynie.
Komunikacja
Otworzyłem dokumentację GDB, zobaczyłem przykładową implementację w kernelu i wziąłem się do roboty - zacząłem pisać przykładową implementację stub-a, aby poznać zasadę działania. Żeby nie zajmować się obsługą gniazd wykorzystałem pewną sztuczkę - mój program komunikuje się z użyciem standardowego wejścia i wyjścia, a ono przekazywane jest do GDB z użyciem komenty netcat (dodam, że pracowałem na Linuksie).
Wcześniej wspomniałem o użyciu portu szeregowego do komunikacji. Oprócz niego obsługiwane są zwykłe sockety, co pozwala na debugowanie kodu przez sieć.
netcat jest prostym narzędziem (na Windowsa dostępny jest ncat) umożliwiającym uruchomienie serwera lub klienta TCP, który będzie przekazywał dane z użyciem gniazd sieciowych. W moim przypadku nasłuchiwał on na porcie 1234, a dane były przekazywane do mojego programu:
$ nc -l -p 1234 -e gdb_stub
# (l - listen, p - port, e - exec)
Ważna uwaga - nc będzie wysyłał dane gdy zostanie naciśnięty enter. Można wymusić wysyłanie co znak używają fflush przy każdym putchar.
Aby debugować kod z innej architektury niż ta na której uruchamiany jest gdb potrzebujemy odpowiedniej wersji. Na Debianie można to wykonując:
$ sudo apt-get install gdb-multiarch
Następnie uruchamiany gdb-multiarch, wydajemy polecenie set arch mips:3000 oraz target remote :1234, które ustawią architekturę na MIPS i spróbują nawiązać połączenie na porcie 1234. Jeżeli uruchomimy nc bez parametru -e w konsoli będą widoczne ciągi znaków podobne do tych:
$g#67
Jest to pakiet od GDB proszący o przesłanie stanu rejestrów. Każdy pakiet trzyma się tej samej struktury
- $ - początek pakietu
- pojedyńczy znak komendy
- ciąg znaków będącymi dodatkowymi parametrami (tutaj brak)
- # - koniec pakietu
- 2 bajty będące sumą kontrolną
GDB oczekuje odpowiedzi:
- '+' lub '-' oznaczające kolejno poprawna ramka, nie poprawna ramka (prośba o retransmisje)
- odpowiedź o strukturze jak powyżej
Implementacja
Budowa pakietu bardzo upraszcza napisanie funkcji obsługującej jej. Ja zastosowałem prostą maszynę stanów:
enum PacketState {
waitingForStart = 0,
reading,
waitingForChecksum1,
waitingForChecksum2
};
Na początku program czeka na rozpoczęcie pakietu
while (1) {
c = getDebugChar();
switch (state) {
case waitingForStart:
if (c == '$') state = reading;
break;
Gdy natrafi na znak $ czyta komendę do bufora aż do napotkania znaku #. Dodatkowo liczona jest suma kontrolna, która polega na sumowaniu wszystkich bajtów pomiędzy $ i #
case reading:
if (c == '#') {
state = waitingForChecksum1;
break;
}
buffer[pos++] = c;
calculatedChecksum += c;
break;
Dwa kolejne stany to pobranie pierwszej i drugiej liczby sumy kontrolnej, weryfikacja i wysłanie '-' lub '+' w zależności od stanu.
case waitingForChecksum1:
checksum = toInt(c) >> 4;
state = waitingForChecksum2;
break;
case waitingForChecksum2:
checksum |= toInt(c);
if (calculatedChecksum != checksum) {
appendToBuffer('-');
return false;
}
appendToBuffer('+');
return true;
Kolejnym krokiem jest rozróżnienie komendy. Do prawidłowego działania GDB oczekuje implementacji 6 pakietów: ‘g’ i ‘G’ - odczyt i modyfikacja rejestrów, ‘m’ and ‘M’ - odczyt i zapis pamięci, ‘c’ - kontynuuj wykonywanie i ‘s’ - wykonywanie krokowe (dokumentacja).
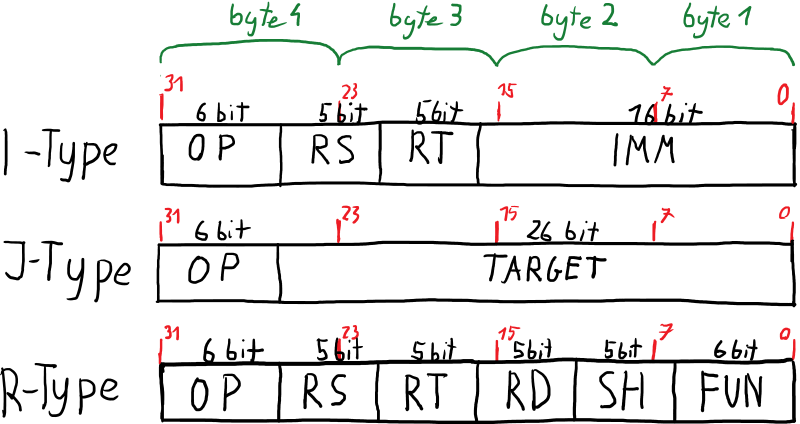
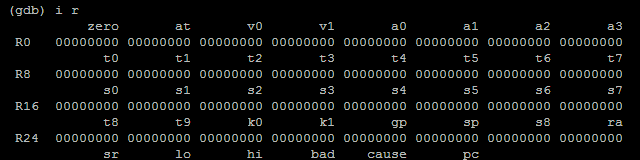
Omówię tylko jedną z nich - 'g'. Debugger oczekuje zrzutu wszystkich rejestrów procesora - 32 rejestrów ogólnych, 6 rejestrów kontrolnych (sr, lo, hi, bad, cause, pc) oraz 35 rejestrów FPU (niedostępne na PS1). Wartości wysyłane są w little endian w formacie hex (wartość 0xBFC00000 będzie wysłana jako 00 00 c0 bf). Rejestry niedostępne oznaczane są jako (xx xx xx xx).
Po kilku godzinnej walce (głupie błędy typu brak fflush, zła ilość wysyłanych rejestrów, zły format pakietu) i implementacji reszty komend GDB myślał, że udało mu podłączyć się z procesorem działającym na architekturze MIPS.
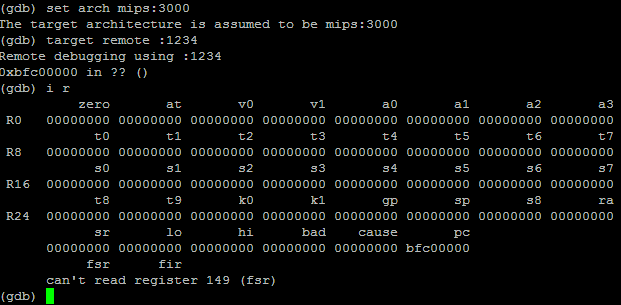
GDB rozmawia z "procesorem"
Komunikacja po sieci
Rozwiązanie z nc bardzo przypadło mi do gustu, ale nie zadziała ono gdy dodam stub do emulatora. Aby zaprogramować obsługę gniazd miałem kilka opcji:
- standardowe Berkeley sockets
- ASIO z Boost
- SDL
Nie wybrałem czystych socketów - wymagają dużej ilości kodu i nie są do końca wieloplatformowe. ASIO ma wielkie możliwości, ale to inny kaliber i nie chciałem dodawać Boosta tylko dla tej funkcjonalności. Wybrałem SDL_net, który jest tak naprawdę nakładką na sockety. Nasłuchiwanie i obsługa połączenia to kilka linii kodu + obsługa błędów.
Dzięki temu mogę uruchomić emulator ze stubem na komputerze lokalnym, a debugger na zdalnej maszynie (nie znalazłem gdb-multiarch na Windowsa) i tunelować ruch po ssh.
Poza GDB są jeszcze inne rozwiązania - IDA wspiera debugowanie z użyciem tego samego protokołu, w dodatku oferując bardzo przyjazny interfejs. Radare2 (darmowa alternatywa) podobno też wspiera ten protokół, ale nie byłem w stanie zmusić go do współpracy.